

Changing TypeScript library functions while keeping backwards compatibility
Changing APIs is a common problem for library authors. There’s some class or function that you need to change, but you don’t want to break your library’s client code when they upgrade the library. In other words, the change needs to be backward compatible. Sure, there are cases when you’ll have to make breaking changes, but it’s usually better to avoid that. In the case of company-internal packages, when you can modify both the library and the app that consumes it, there are a few nifty patterns to deal with API changes.

Premature Infrastructure is the Root of All Evil
Premature infrastructure is a peculiar behavior pattern that I witnessed in every single tech company I worked for. It is the habit of creating infrastructure code before it is actually needed. The development team is predicting future requirements and preparing ahead of time. That might be preparation for a future feature, extension capabilities that aren’t needed yet, or customization that may or may not be wanted. I believe that creating premature infrastructures is one of the biggest problems in software development.

Continuous Delivery with Feature Flags (toggles) is More Difficult Than it Seems
What happens if you’re working on something that lasts much more than one sprint? Maybe 3 sprints or 10. Are you going to work on a separate branch, ending with a huge merge? Are you going to run automated tests on that branch? This matter is not that simple, as I recently experienced.

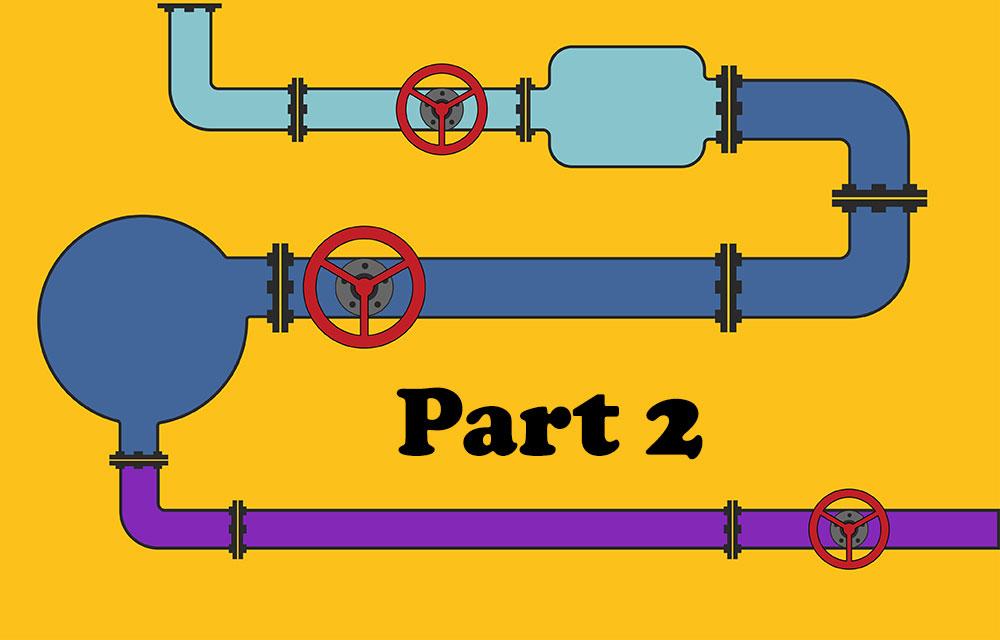
Pipeline Implementations in C#: TPL Dataflow Async steps and Disruptor-net
In the 3rd part of the series we'll see how to create asynchronous steps in the pipeline with TPL Dataflow. We'll also see a new implementation using the Disruptor-net library.
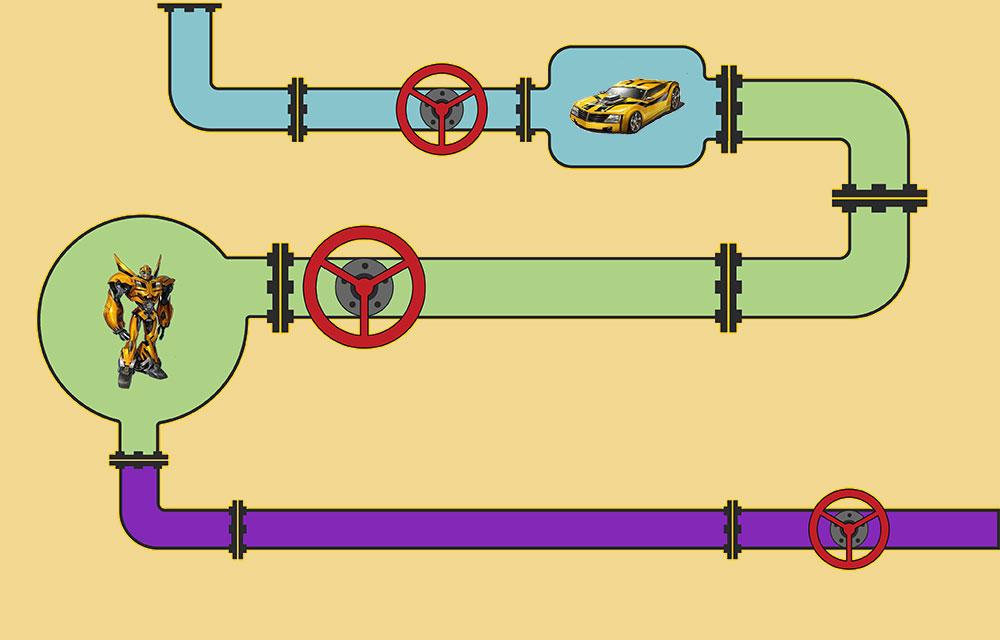
Pipeline Pattern in C# (part 2) with TPL Dataflow
In the First Part of the series, we talked about the Pipeline Pattern in programming, also known as the Pipes and Filters design pattern. In this part, we'll see how to implement such a pipeline with TPL Dataflow.
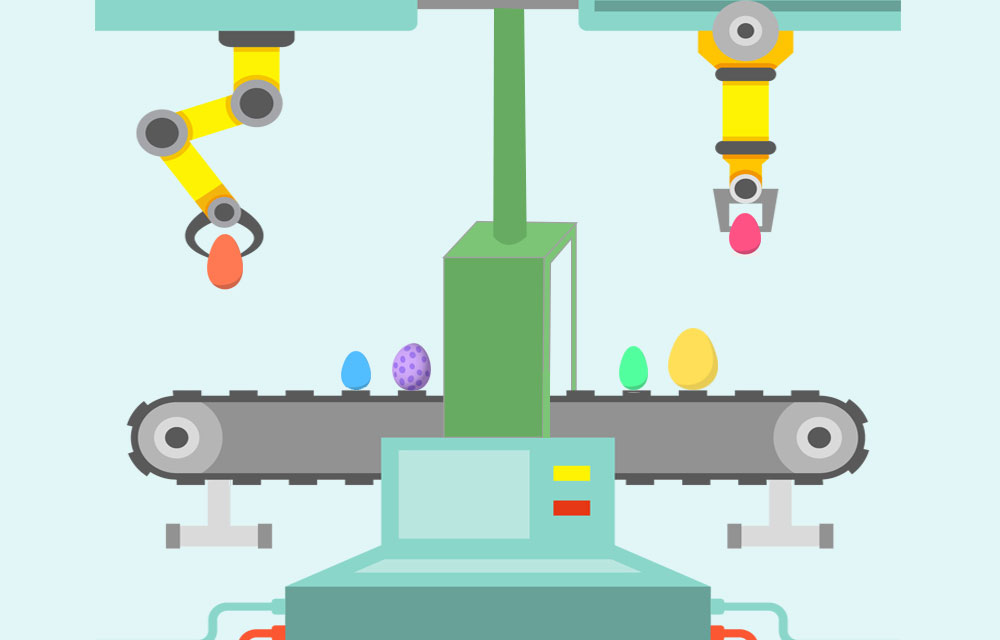
Pipeline Pattern Implementations in C# .NET - Part 1
The Pipeline pattern is a powerful tool in programming. The idea is to chain a group of functions in a way that the output of each function is the input the next one. The concept is pretty similar to an assembly line where each step manipulates and prepares the product for the next step.
Class Instantiation Guidelines in Object Oriented Languages: When to choose Singleton, Static, Extension methods or Dependency Injection
I'd like to tackle an old dilemma: Class instantiation. Which pattern do you use to create a class? Do you always use a new statement? Do we still need to use Singleton or Factory? Should we always use dependency injection? How about static classes, are they truly evil?

Performance Showdown of Producer/Consumer (Job Queues) Implementations in C# .NET
I recently wrote 3 blog posts on different Producer/Consumer (Job Queues) implementations. In this article, we will compare performance of all the approaches, including...

C# Job Queues (part 3) with TPL Dataflow and Failure Handling
In this article, we'll see how to implement Job Queues with TPL Dataflow, including implementations of several of the said variations. We will dive into the Dataflow mindset along the way, figuring out this awesome library.