
The Battle of C# to JSON Serializers in .NET Core 3
.NET Core 3 was recently released and brought with it a bunch of innovations. Besides C# 8 and support for WinForms & WPF, the new release added a brand new JSON (de)serializer. This new serializer goes by the name System.Text.Json and as the name suggests, all its classes are in that namespace.
This is a big deal. JSON serialization is a big factor in web applications. Most of today’s REST API relies on it. When your javascript client sends a JSON request in a POST body, the server uses JSON deserialization to convert it to a C# object. And when the server returns an object in its response, it serializes that object into JSON for your JavaScript client to understand. These are major operations that happen on every request with objects. Their performance can significantly impact application performance as you’re about to see.
If you’ve been working with .NET for some time, then you should know the excellent Json.NET serializer, also known as Newtonsoft.Json. So why do we need a new serializer if we already got Newtonsoft.Json? While Newtonsoft.Json is great, there are several good reasons to replace it:
- Microsoft wanted to make use of the new types like
Span<T>to improve performance. Modifying a huge library like Newtonsoft without breaking functionality is very difficult. - Most network protocols, including HTTP, use UTF-8 text. The type
stringin .NET is UTF-16. Newtonsoft transcodes UTF-8 into UTF-16 strings in its work, compromising performance. The new serializer uses UTF-8 directly. - Since Newtonsoft is a 3rd party library and not part of the .NET Framework (BCL or FCL classes), you might have projects with dependencies on different versions. ASP.NET Core itself is dependent on Newtonsoft, which results in many version conflicts .
In this blog post, we’re going to do some performance benchmarks to see just how much the new serializer improved performance. Except that we’re also going to compare both Newtonsoft.Json and System.Text.Json to other major serializers and see how they fare against each other.
The Battling Serializers
Here’s our lineup:
- Newtonsoft.Json (also known as Json.NET) – The current industry-standard serializer. Was integrated into ASP.NET even though it was 3rd party. #1 NuGet package of all times. Award-winning library (probably, I don’t know).
- System.Text.Json – The brand new serializer by Microsoft. Supposedly faster and better than Newtonsoft.Json. Integrated by default with the new ASP.NET Core 3 projects. It’s part of the .NET framework itself, so there are no NuGet dependencies needed (and no more version conflicts either).
- DataContractJsonSerializer – An older, Microsoft-developed serializer that was integrated in previous ASP.NET versions until Newtonsoft.Json replaced it.
- Jil
– A fast JSON serializer based on Sigil

- ServiceStack
– .NET serializer to JSON, JSV, and CSV. A self-proclaimed fastest .NET text serializer (meaning not binary).

- Utf8Json
– Another self proclaimed fastest C# to JSON serializer. Works with zero allocations and read/writes directly to the UTF8 binary for performance.

Note that there are non-JSON serializers that are faster. Most notably, protobuf-net is a binary serializer that should be faster than any of the compared serializers in this article (though not verified in the benchmarks).
Benchmark structure
It’s not so easy to compare serializers. We’ll need to compare both serialization and deserialization. We’ll need to compare different types of classes (small and big), Lists, and Dictionaries. And we’ll need to compare serialization targets: strings, streams, and char arrays (UTF-8 arrays). That’s a pretty big matrix of benchmarks, but I’ll try to do it as organized and concise as possible.
We’ll test 3 different functionalities:
- Serialization to string
- Serialization to stream
- Deserialization from string
- Requests per second with an ASP.NET Core 3 application
For each, we’ll test different types of objects (which you can see in GitHub ):
- A small class with just 3 primitive-type properties
- A bigger class with about 25 properties, a
DateTimeand a couple of enums - A List with 1000 items (of the small class)
- A Dictionary with 1000 items (of the small class)
It’s not all of the required benchmarks, but it’s a pretty good indicator I think.
For all benchmarks, I used BenchmarkDotNet
with the following system: BenchmarkDotNet=v0.11.5, OS=Windows 10.0.17134.1069 (1803/April2018Update/Redstone4) Intel Core i7-7700HQ CPU 2.80GHz (Kaby Lake), 1 CPU, 8 logical and 4 physical cores. .NET Core SDK=3.0.100. Host : .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), 64bit RyuJIT. The Benchmark project itself is on GitHub
.
Everything will be tested only in .NET Core 3 projects.
Benchmark 1: Serializing to String
The first thing we’ll test is serializing our different objects to a string.
The benchmark code itself is pretty straightforward (see on GitHub ):
public class SerializeToString<T> where T : new()
{
private T _instance;
private DataContractJsonSerializer _dataContractJsonSerializer;
[GlobalSetup]
public void Setup()
{
_instance = new T();
_dataContractJsonSerializer = new DataContractJsonSerializer(typeof(T));
}
[Benchmark]
public string RunSystemTextJson()
{
return JsonSerializer.Serialize(_instance);
}
[Benchmark]
public string RunNewtonsoft()
{
return JsonConvert.SerializeObject(_instance);
}
[Benchmark]
public string RunDataContractJsonSerializer()
{
using (MemoryStream stream1 = new MemoryStream())
{
_dataContractJsonSerializer.WriteObject(stream1, _instance);
stream1.Position = 0;
using var sr = new StreamReader(stream1);
return sr.ReadToEnd();
}
}
[Benchmark]
public string RunJil()
{
return Jil.JSON.Serialize(_instance);
}
[Benchmark]
public string RunUtf8Json()
{
return Utf8Json.JsonSerializer.ToJsonString(_instance);
}
[Benchmark]
public string RunServiceStack()
{
return SST.JsonSerializer.SerializeToString(_instance);
}
}
The above benchmark class is generic, so we can test all of the different objects with the same code, like this:
BenchmarkRunner.Run<SerializeToString<Models.BigClass>>();
After running all class types with all the serializers, here are the results:
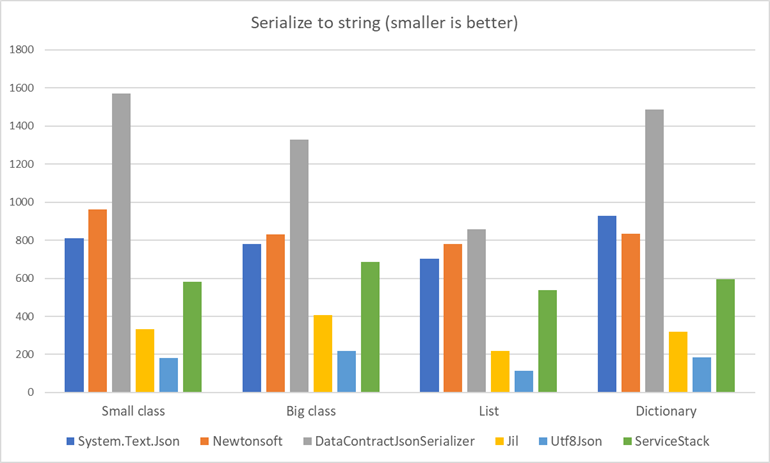
The actual numbers of the results can be seen here
- Utf8Json is fastest by far, over 4 times faster than Newtonsoft.Json and System.Text.Json. This is a pretty amazing difference.
- Jil is also very fast, about 2.5 times faster than Newtonsoft.Json and System.Text.Json.
- The new serializer System.Text.Json is doing better than Newtonsoft.Json in most cases by about 10%, except for Dictionary where it does worst by 10%.
- The older DataContractJsonSerializer is worst than all others by far.
- ServiceStack is right there in the middle, showing that it’s no longer the fastest text serializer. At least not for JSON.
Benchmark 2: Serializing to Stream
The second set of benchmarks is very similar, except that we serialize to stream. The benchmark’s code is here . And the results:
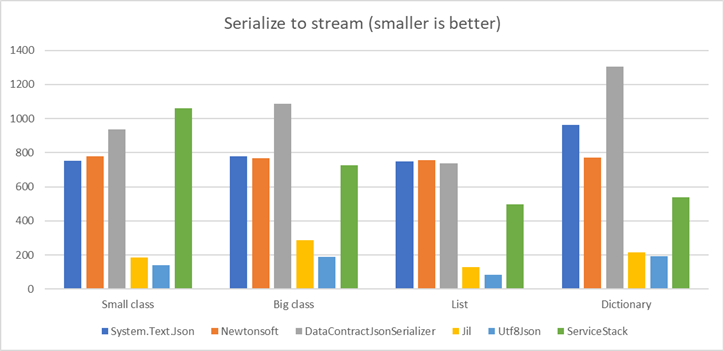
The actual numbers of the results can be seen here . Thanks to Adam Sitnik and Ahson Khan for helping me to get System.Text.Json to work.
The results are pretty similar to before. Utf8Json and Jil are as much as 4 times faster than the others. Jil performed better, a close second to Utf8Json. DataContractJsonSerializer is still slowest in most cases. Newtonsoft actually performed than before – as well as System.Text.Json for most cases and better than System.Text.Json for Dictionary.
Benchmark 3: Deserializing from String
The next set of benchmarks is about deserialization from string. The benchmark code can be found here .

The actual numbers of the results can be seen here
I had a hard time with DataContractJsonSerializer on this one, so it’s not included. We can see that in deserialization Jil is fastest, with Utf8Json a close second. Those two are 2-3 times faster than System.Text.Json. And System.Text.Json is about 30% faster than Json.NET.
So far, looks like the popular Newtonsoft.Json and the newcomer System.Text.Json have significantly worse performance than some of the others. This was pretty surprising to me due to Newtonsoft.Json’s popularity and all the hype around Microsoft’s new top-performer System.Text.Json. Let’s test it even further in an ASP.NET application.
Benchmark 4: Requests per Second by a .NET server
As mentioned before, JSON serialization is so very important because it constantly occurs in REST API. HTTP requests to a server that use the content-type application/json will need to serialize or deserialize a JSON object. When a server accepts a payload in a POST request, the server is deserializing from JSON. When a server returns an object in its response, it’s serializing JSON. Modern client-server communication heavily relies on JSON serialization. That’s why to test a “real world” scenario, it makes sense to create a test server and measure its performance.
I was inspired by Microsoft’s performance test where they created an MVC server application and tested requests per second. Microsoft’s benchmark tests System.Text.Json vs Newtonsoft.Json. In this article, we’re going to do the same, except that we’re going to compare them to Utf8Json which proved to be one of the fastest serializer in the previous benchmarks.
Unfortunately, I wasn’t able to integrate ASP.NET Core 3 with Jil, so the benchmark doesn’t include it. I’m absolutely sure it’s possible with some more effort.
Building this test proved more challenging than before. First, I created an ASP.NET Core 3.0 MVC application, just like in MS’s test. I added a controller for the performance tests that’s kind of similar to the one in MS’s test :
[Route("mvc")]
public class JsonSerializeController : Controller
{
private static Benchmarks.Serializers.Models.ThousandSmallClassList _thousandSmallClassList
= new Benchmarks.Serializers.Models.ThousandSmallClassList();
[HttpPost("DeserializeThousandSmallClassList")]
[Consumes("application/json")]
public ActionResult DeserializeThousandSmallClassList([FromBody]Benchmarks.Serializers.Models.ThousandSmallClassList obj) => Ok();
[HttpGet("SerializeThousandSmallClassList")]
[Produces("application/json")]
public object SerializeThousandSmallClassList() => _thousandSmallClassList;
}
When the client will call the endpoint DeserializeThousandSmallClassList, the server will accept a JSON text and deserialize the content. This tests deserialization. When the client will call SerializeThousandSmallClassList, the server will return a list of 1000 SmallClass items and by doing that will serialize the content to JSON.
Next, we need to cancel logging on each request so it won’t affect the result:
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureLogging(logging =>
{
logging.ClearProviders();
//logging.AddConsole();
})
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
});
Now we need a way to switch between System.Text.Json, Newtonsoft, and Utf8Json. For the first two, the switch is easy. Doing nothing will work with System.Text.Json. To switch to Newtonsoft.Json, just add one line in ConfigureServices :
public void ConfigureServices(IServiceCollection services)
{
services.AddControllersWithViews()
//Uncomment for Newtonsoft. When commented, it uses the default System.Text.Json
.AddNewtonsoftJson()
;
For Utf8Json, we’ll need to add custom InputFormatter and OutputFormatter media formatters. This was a bit challenging, but eventually, I found a good solution online
and after a few tweaks it worked. There’s also a NuGet package
with the formatters, but it doesn’t work with ASP.NET Core 3.
internal sealed class Utf8JsonInputFormatter : IInputFormatter
{
private readonly IJsonFormatterResolver _resolver;
public Utf8JsonInputFormatter1() : this(null) { }
public Utf8JsonInputFormatter1(IJsonFormatterResolver resolver)
{
_resolver = resolver ?? JsonSerializer.DefaultResolver;
}
public bool CanRead(InputFormatterContext context) => context.HttpContext.Request.ContentType.StartsWith("application/json");
public async Task<InputFormatterResult> ReadAsync(InputFormatterContext context)
{
var request = context.HttpContext.Request;
if (request.Body.CanSeek && request.Body.Length == 0)
return await InputFormatterResult.NoValueAsync();
var result = await JsonSerializer.NonGeneric.DeserializeAsync(context.ModelType, request.Body, _resolver);
return await InputFormatterResult.SuccessAsync(result);
}
}
internal sealed class Utf8JsonOutputFormatter : IOutputFormatter
{
private readonly IJsonFormatterResolver _resolver;
public Utf8JsonOutputFormatter1() : this(null) { }
public Utf8JsonOutputFormatter1(IJsonFormatterResolver resolver)
{
_resolver = resolver ?? JsonSerializer.DefaultResolver;
}
public bool CanWriteResult(OutputFormatterCanWriteContext context) => true;
public async Task WriteAsync(OutputFormatterWriteContext context)
{
if (!context.ContentTypeIsServerDefined)
context.HttpContext.Response.ContentType = "application/json";
if (context.ObjectType == typeof(object))
{
await JsonSerializer.NonGeneric.SerializeAsync(context.HttpContext.Response.Body, context.Object, _resolver);
}
else
{
await JsonSerializer.NonGeneric.SerializeAsync(context.ObjectType, context.HttpContext.Response.Body, context.Object, _resolver);
}
}
}
Now to have ASP.NET use these formatters:
public void ConfigureServices(IServiceCollection services)
{
services.AddControllersWithViews()
//Uncomment for Newtonsoft
//.AddNewtonsoftJson()
//Uncomment for Utf8Json
.AddMvcOptions(option =>
{
option.OutputFormatters.Clear();
option.OutputFormatters.Add(new Utf8JsonOutputFormatter1(StandardResolver.Default));
option.InputFormatters.Clear();
option.InputFormatters.Add(new Utf8JsonInputFormatter1());
});
}
So this is it for the server. Now for the client.
C# Request-per-Second Client
I built a client application in C# as well, though most real-world scenarios will have JavaScript clients. For our purposes, it doesn’t really matter. Here’s the code:
public class RequestPerSecondClient
{
private const string HttpsLocalhost = "https://localhost:5001/";
public async Task Run(bool serialize, bool isUtf8Json)
{
await Task.Delay(TimeSpan.FromSeconds(5));
var client = new HttpClient();
var json = JsonConvert.SerializeObject(new Models.ThousandSmallClassList());
// Warmup, just in case
for (int i = 0; i < 100; i++)
{
await DoRequest(json, client, serialize);
}
int count = 0;
Stopwatch sw = new Stopwatch();
sw.Start();
while (sw.Elapsed < TimeSpan.FromSeconds(1))
{
count++;
await DoRequest(json, client, serialize);
}
Console.WriteLine("Requests in one second: " + count);
}
private async Task DoRequest(string json, HttpClient client, bool serialize)
{
if (serialize)
await DoSerializeRequest(client);
else
await DoDeserializeRequest(json, client);
}
private async Task DoDeserializeRequest(string json, HttpClient client)
{
var uri = new Uri(HttpsLocalhost + "mvc/DeserializeThousandSmallClassList");
var content = new StringContent(json, Encoding.UTF8, "application/json");
var result = await client.PostAsync(uri, content);
result.Dispose();
}
private async Task DoSerializeRequest(HttpClient client)
{
var uri = HttpsLocalhost + "mvc/SerializeThousandSmallClassList";
var result = await client.GetAsync(uri);
result.Dispose();
}
}
This client will send continuous requests for 1 second while counting them.
Results
So without further ado, here are the results:
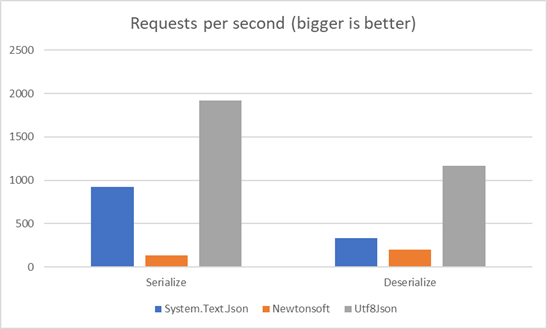
The actual numbers of the results can be seen here
Utf8Json outperformed the other serializers by a landslide. This shouldn’t come as a big surprise after the previous benchmarks.
For serialization, Utf8Json is 2 times faster than System.Text.Json and a whole 4 times faster than Newtonsoft. For deserialization, Utf8Json is 3.5 times faster than System.Text.Json and 6 times faster than Newtonsoft.
The only surprise here is how poorly Newtonsoft.Json performed. This is probably due to the UTF-16 and UTF-8 issue. The HTTP protocol works with UTF-8 text. Newtonsoft converts this text into .NET string types, which are UTF-16. This overhead is not done in either Utf8Json or System.Text.Json, which work directly with UTF-8.
It’s important to mention that this benchmark should be taken with a grain of salt since it might not fully reflect a real-world scenario. Here’s why:
- I ran everything on my local machine, both client and server. In a real-world scenario, the server and client are on different machines.
- The client sends requests one after another in a single thread. This means the server doesn’t accept more than one request at a time. In a real-world scenario, your server will accept requests on multiple threads from different machines. These serializers may act differently when serving multiple requests at a time. Perhaps some use more memory for better performance, which will not do so well with multiple operations at a time. Or perhaps some create GC Pressure . This is not likely with Utf8Json which does no allocations.
- In Microsoft’s test , they achieved much more requests per second (over 100,000 in some cases). Sure, this probably has to do with the above 2 points and a smaller payload, but still, this is suspicious.
- Benchmarks are easy to get wrong. It’s possible that I missed something or that the server can be optimized with some configuration.
Having said all of the above, these results are pretty incredible. It seems that you can significantly improve response time by changing a JSON serializer. Changing from Newtonsoft to System.Text.Json will improve requests amount by 2-7 times and changing from Newtonsoft to Utf8Json will improve by the huge factor of 6 to 14. This is not entirely fair because a real server will do much more than just accept arguments and return objects. It will probably do other stuff as well, like go to a database and so some business logic, so serialization time might play a lesser role. Still, these numbers are pretty incredible.
Conclusions
Let’s do a summary of everything so far:
- The newer System.Text.Json serializer is in most cases faster than Newtonsoft.Json in all benchmarks. Kudos to Microsoft for a job well done.
- 3rd party serializers proved to be faster than both Newtonsoft.Json and System.Text.Json. Specifically Utf8Json and Jil are about 2-4 times faster than System.Text.Json.
- The requests-per-seconds scenario showed that Utf8Json can be integrated with ASP.NET and significantly increase request throughput. Thought as mentioned, this is not a full real world scenario and I suggest doing additional benchmarks if you plan to change serializers in your ASP.NET app.
Does this mean we should all change to Utf8Json or Jil? The answer to that is… maybe. Remember that Newtonsoft.Json stood the test of time and became the most popular serializer for a reason. It supports a lot of features, was tested with all kinds of edge cases and has a ton of documented solutions and workarounds. Both System.Text.Json and Newtonsoft.Json are extremely well supported. Microsoft will continue to invest resources and effort into System.Text.Json so you’re going to get excellent support. Whereas Jil and Utf8Json have had very few commits in the last year. In fact, it looks like they didn’t have much maintenance done in the last 6 months.
One options is to combine several serializers in your app. Change to the faster serializers for ASP.NET integration to achieve superior performance, but keep using Newtonsoft.Json in business logic to leverage its feature set.
I hope you enjoyed this one, cheers.
Other Benchmarks
Several other benchmarks compare the different serializers:
- On Microsoft’s announcement of System.Text.Json, they released their own performance benchmark comparing between System.Text.Json and Newtonsoft.Json. In addition to serialization and deserialization, this benchmark compares Document class for random access, Reader, and Writer. They also release their Requests-per-second test that inspired me to do my own.
- .NET Core’s GitHub repository includes a bunch of benchmarks similar to the ones in this article. In fact, I looked very closely at their benchmarks to make sure I’m not doing any mistakes. You can find these in the Micro-benchmarks solution .
- Jil have their own benchmarks that compare Jil, Newtonsoft, Protobuf, and ServiceStack.
- Utf8Json published a set of benchmarks available on GitHub . These also compare to binary serializers.
- Alois Kraus did a great in-depth benchmark between the most popular .NET serializers, including JSON serializers, Binary serializers, and XML serializers. His benchmark includes both .NET Core 3 and .NET Framework 4.8 benchmarks.



